Clearing Up Misunderstandings: Sequestration Would Not Be Tougher on Defense Than Non-Defense Programs in 2014
As Congress sets program funding levels for fiscal year 2014, it must determine whether to replace the sequestration cuts called for in the 2011 Budget Control Act (BCA) — reductions that would come on top of cuts in defense and non-defense programs that have occurred since 2010 — with alternative deficit reduction measures.
Under current law, the sequestration cuts in 2014 total $109 billion, evenly split between defense and non-defense programs. The savings come from reducing discretionary appropriations below the pre-sequestration cap levels set in the BCA and from a select group of largely non-defense entitlements (primarily Medicare).
If sequestration remains in effect, non-defense discretionary funding in 2014 will be at about the same level as in 2013, while defense funding will be $20 billion below its 2013 funding level. This would occur largely because Congress made one-time changes to the BCA in the “fiscal cliff” bill that caused defense to be cut $20 billion less in 2013 than the BCA would have originally required under sequestration. In contrast, these changes had little net effect on funding for non-defense programs in 2013, causing it to be cut by roughly the same amount as originally called for.
A core principle of the sequestration provisions of the BCA is that sequestration cuts would be evenly divided between defense and non-defense programs. This is why, under sequestration, defense funding will drop $20 billion from 2013 to 2014 while non-defense discretionary funding will stay basically flat; this restores the 50-50 split the BCA intended between defense and non-defense programs.
The impression some have that the 2014 sequestration will hit defense harder than non-defense programs — or target defense disproportionately — is mistaken.
Moreover, policymakers have cut non-defense discretionary programs more deeply than defense since 2010, when they began efforts to shrink deficits, and this will continue to be the case in 2014 even if sequestration remains in effect.
Thus policymakers should resist calls to provide relief from sequestration only to defense programs; any relief should also include increased funding for non-defense discretionary programs, adhering to the BCA’s core principle of maintaining parity in sequestration cuts between defense and non-defense.
Changes to 2013 Funding Levels Reduced the Defense Cuts
Congress has cut funding substantially for both non-defense discretionary programs and defense since 2010. The cuts are largely due to the BCA, which capped discretionary funding and called for additional sequestration cuts if Congress failed to enact deficit-reduction legislation through the “supercommittee” process.
Under the BCA, total discretionary funding after sequestration is capped at $967 billion in 2014. This is $19 billion below the actual 2013 post-sequestration funding level, according to the Congressional Budget Office (CBO).[1] Virtually all of that difference is in defense. Thus, to comply with sequestration in 2014, defense funding must come down about $20 billion relative to 2013, while funding for non-defense discretionary programs would essentially remain flat.
| Table 1 2014 Discretionary Levels (billions of dollars) | |||
| Freeze at 2013 level after sequestration | Budget Control Act cap before sequestration | Budget Control Act cap after sequestration | |
| Defense | 518 | 552 | 498 |
| Non-defense | 468 | 506 | 469 |
| Total | 986* | 1058 | 967 |
| * Early analyses had typically set the 2013 level at $988 billion. This was only an approximation of how a freeze of 2013 appropriations language would be scored in 2014. The $986 billion estimated used in this analysis reflects the CBO scoring of H. J. Res. 59, which would continue the 2013 levels with only a few exceptions. | |||
At first blush, this result may appear surprising, given that the BCA called for equal treatment of defense and non-defense programs. In fact, these defense reductions in 2014 are needed to restore the parity between defense and non-defense programs that the BCA requires, but which policymakers circumvented in 2013.
Originally, the BCA’s defense and non-defense caps were slated to rise by nearly identical amounts between 2013 and 2014. The American Taxpayer Relief Act (ATRA, the “fiscal cliff” bill, enacted in January 2013) changed the story. It cancelled two months of sequestration, reducing the 2013 sequestration cuts and thereby raising the 2013 post-sequestration funding levels. It also lowered the 2014 caps to help recapture some of the lost savings from 2013. As a result of these changes, the 2013 funding levels under sequestration were higher than the revised 2014 sequestration levels, by roughly equal amounts for defense and non-defense discretionary programs. These changes thus maintained the BCA’s intended parity between defense and non-defense programs.
But ATRA also changed the composition of the two discretionary funding caps for 2013 only, from a cap on "defense" and a cap on "non-defense discretionary" funding to a cap on "security" funding and a cap on "non-security" funding. Security is a broader budget category than defense; it also includes areas such as international affairs, homeland security, and veterans' programs. Congress then proceeded to provide more funding for the defense portion of the security category than the original defense cap for 2013 would have allowed. These new caps allowed Congress to change the composition of discretionary funding without changing the total amount.
Because of these changes and one other technical factor, defense programs ended up bearing roughly $20 billion less in cuts in 2013 than sequestration originally called for, while the amount of non-defense discretionary cuts in 2013 remained essentially unchanged. (The various changes that ATRA made to non-defense discretionary funding in 2013 essentially offset each other.) This is why the post-sequestration caps for 2014, which adhere to the equal treatment principle that was a core element of the BCA, require that cuts from 2013 to 2014 come from defense rather than non-defense funding.
Non-Defense Reductions Since 2010 Exceed Defense Reductions
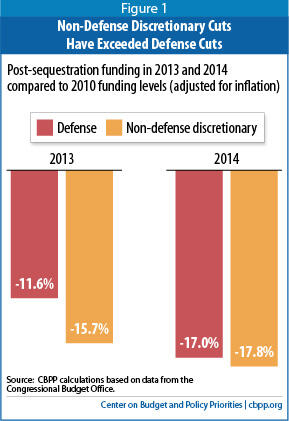
As Figure 1 shows, through 2013, non-defense discretionary funding has fallen more sharply than defense funding, relative to the 2010 funding levels. Overall funding for non-defense discretionary programs in 2013 is nearly 16 percent lower than in 2010, adjusted for inflation, while defense funding has declined less than 12 percent.
If sequestration continues in 2014, the amount of cuts to both program areas will be much more similar, although the non-defense discretionary cuts will still outpace the defense cuts by a small margin.[3] That is, if Congress holds non-defense discretionary funding constant in 2014 while reducing defense by $20 billion, the percentage cuts in the two spending categories since 2010 will be nearly equal.
Conclusion
The 2014 post-sequestration funding levels for defense and non-defense programs maintain the core BCA principle that sequestration must take half of its cuts from defense and half from non-defense (including Medicare and some other non-defense entitlements). As Congress considers replacing sequestration, it should adhere to that parity principle, which policymakers adopted in the BCA because Republicans strongly preferred it to the Administration’s proposal to split sequestration 50-50 between spending cuts and revenues.
Further, Congress should not ignore the significant funding gaps in critical public services on the non-defense side of the discretionary budget. Holding non-defense funding constant between 2013 and 2014 would mean that all of the cuts made this year will continue next year, and, in many cases, the impact of those cuts will be larger in 2014 than in 2013. One reason is that inflation will erode funding; another is that many agencies cushioned the impact of the 2013 sequestration where possible by using one-time measures such as delaying needed purchases or repairs or relying on unused 2012 funding. Many such one-time “fixes” will not be available (at all or to the same degree) again next year. These and other factors, including the impact of sequestration on defense, are reasons that Congress should replace sequestration with a sound package of balanced deficit-reduction measures that take effect as the economy strengthens.
End Notes
[1] Congressional Budget Office, Letter to Honorable Paul Ryan, September 12, 2013. This is CBO’s estimate of H. J. Res 59, the continuing resolution for FY 2014 introduced by House Appropriations Committee Chairman Hal Rogers. The bill continues the 2013 post-sequestration level in 2014 with only minor changes. The estimate reflects the cost under the resolution if it were in effect for the full year.
[2] The one-time changes that increased defense funding in 2013 by $20 billion (compared to the level the BCA originally would have required for defense in 2013 under sequestration) consist of $8 billion in funding from shrinking the overall size of the 2013 sequestration and lowering the 2013 cap, $8 billion from shifting cuts from defense to international affairs and homeland security programs, and $4 billion from a technical factor in the application of sequestration known as “crediting.”
[3] About $17 billion per year in non-defense cuts have been accomplished through appropriations language changing mandatory programs, called CHIMPs. These estimates take into account these CHIMP savings in all years.
More from the Authors

Areas of Expertise

Areas of Expertise
